[JPA] N+1 문제
준비
- Team 이 부모이고, Student는 자식들의 부모관계로 설정하고 양방향 관계로 설정을 하였다.
- 축구팀에는 2명의 학생, 농구팀에도 2명의 학생을 배정하였다.
- Fetch Type을 Eager로 사전 로딩을 세팅해뒀다.
- 1차 캐시를 사용하지 않기 위해,
setup()마지막에session.evit()을 호출하여 캐시를 삭제하고, 테스트 코드를 실행한다.
@Entity
@Getter
public class Team {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String name;
@JsonManagedReference
@OneToMany(mappedBy = "team", fetch = FetchType.EAGER)
private List<Student> students = new ArrayList<>();
public static Team of(String name) {
Team team = new Team();
team.name = name;
return team;
}
}@Entity
@Getter
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String name;
@JsonBackReference
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn
private Team team;
public static Student of(String name, Team team) {
Student student = new Student();
student.name = name;
student.team = team;
team.join(student);
return student;
}단일 조회로 성능상 문제없는 상황
@Test
void 단일_조회합니다() {
// Given
Team team = teamRepository.findById(축구팀.getId()).orElseThrow();
// When
List<Student> students = team.getStudents();
// Then
assertThat(students).containsAll(학생들);
}Hibernate:
select
team0_.id as id1_1_0_,
team0_.name as name2_1_0_,
students1_.team_id as team_id3_0_1_,
students1_.id as id1_0_1_,
students1_.id as id1_0_2_,
students1_.name as name2_0_2_,
students1_.team_id as team_id3_0_2_
from
team team0_
left outer join
student students1_
on team0_.id=students1_.team_id
where
team0_.id=?N개 조회 시 성능 문제 발생
@Test
void 모든_팀을_조회() {
// Given
List<Team> teams = teamRepository.findAll();
log.info(teams.toString());
// When
List<Student> students = teams.stream()
.map(Team::getStudents)
.flatMap(Collection::stream)
.collect(Collectors.toList());
// Then
assertThat(students).containsAll(학생들);
}Hibernate:
select
team0_.id as id1_1_,
team0_.name as name2_1_
from
team team0_
Hibernate:
select
students0_.team_id as team_id3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.name as name2_0_1_,
students0_.team_id as team_id3_0_1_
from
student students0_
where
students0_.team_id=?
2022-08-06 16:39:03.572 TRACE 22571 --- [ main] o.h.type.descriptor.sql.BasicBinder : binding parameter [1] as [BIGINT] - [4]
Hibernate:
select
students0_.team_id as team_id3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.name as name2_0_1_,
students0_.team_id as team_id3_0_1_
from
student students0_
where
students0_.team_id=?
2022-08-06 16:39:03.577 TRACE 22571 --- [ main] o.h.type.descriptor.sql.BasicBinder : binding parameter [1] as [BIGINT] - [1]
2022-08-06 16:39:03.580 INFO 22571 --- [ main] com.example.demojpatest.NPlusOneTest : [Team{id=1, name='축구팀', students.size=2}, Team{id=4, name='농구팀', students.size=2}]
2022-08-06 16:39:03.611 INFO 22571 --- [ main] com.example.demojpatest.NPlusOneTest : [Student{id=2, name='학생1', team=Team{id=1, name='축구팀', students.size=2}}, Student{id=3, name='학생2', team=Team{id=1, name='축구팀', students.size=2}}, Student{id=5, name='학생3', team=Team{id=4, name='농구팀', students.size=2}}, Student{id=6, name='학생4', team=Team{id=4, name='농구팀', students.size=2}}]로그를 보면, Team 전체 조회를 하면 2개가 반환된다. 그리고 각 팀에 있는 학생들을 다시 조회한다.
- 팀 조회
- 축구팀에 속한 학생들 조회
- 농구팀에 속한 학생들 조회
총 3개의 쿼리가 발생했다. 지금은 팀 개수가 2개 밖에 없어서 성능상 문제는 없지만, 실제로 팀 갯수가 백만 개라면 최대 백만 개의 학생 조회하는 쿼리가 발생할 수 있다.
대상 엔터티를 조회되면, 연관된 엔터티를 조회하는 추가적인 쿼리가 발생하는 문제를 N+1 문제라 한다.
N+1 문제 보완책: Lazy Loading (해결책X)
지연 로딩은 연관관계에 있는 엔터티를 접근할 때 조회 쿼리를 함으로써 성능을 효율화시킬 수 있는 설정이다.
아래는 팀의 연관 관계인 학생들을 조회하지 않으니 팀 조회 쿼리 1개만 발생했다.
@Test
void 모든_팀을_지연로딩_조회() {
// When
List<Team> teams = teamRepository.findAll();
// Then
assertThat(teams).hasSize(2);
}Hibernate:
select
team0_.id as id1_1_,
team0_.name as name2_1_
from
team team0_아래에서 한 개의 팀만 조회하면, 해당 팀의 학생들을 조회하는 쿼리가 발생한다.
@Test
void 모든_팀을_지연로딩_조회() {
// Given
List<Team> teams = teamRepository.findAll();
// When
log.info(teams.get(0).getStudents().toString());
// Then
assertThat(teams).hasSize(2);
}Hibernate:
select
team0_.id as id1_1_,
team0_.name as name2_1_
from
team team0_
Hibernate:
select
students0_.team_id as team_id3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.name as name2_0_1_,
students0_.team_id as team_id3_0_1_
from
student students0_
where
students0_.team_id=?
2022-08-06 17:01:28.010 TRACE 23928 --- [ main] o.h.type.descriptor.sql.BasicBinder : binding parameter [1] as [BIGINT] - [1]하지만 밑에서 보면 팀의 학생들을 Loop를 돌며 전체 조회를 하면, 결국 즉시 로딩과 똑같이 N+1 문제로 쿼리 개수가 팀 개수만큼 발생한다.
@Test
void 모든_팀을_조회() {
// When
List<Team> teams = teamRepository.findAll();
log.info(teams.toString());
List<Student> students = teams.stream()
.map(Team::getStudents)
.flatMap(Collection::stream)
.collect(Collectors.toList());
// Then
assertThat(students).containsAll(학생들);
log.info(students.toString());
}Hibernate:
select
team0_.id as id1_1_,
team0_.name as name2_1_
from
team team0_
Hibernate:
select
students0_.team_id as team_id3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.name as name2_0_1_,
students0_.team_id as team_id3_0_1_
from
student students0_
where
students0_.team_id=?
2022-08-06 17:08:24.659 TRACE 24327 --- [ main] o.h.type.descriptor.sql.BasicBinder : binding parameter [1] as [BIGINT] - [1]
Hibernate:
select
students0_.team_id as team_id3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.name as name2_0_1_,
students0_.team_id as team_id3_0_1_
from
student students0_
where
students0_.team_id=?
2022-08-06 17:08:24.666 TRACE 24327 --- [ main] o.h.type.descriptor.sql.BasicBinder : binding parameter [1] as [BIGINT] - [4]해결책1: 패치 조인 Fetch Join 사용
패치 조인을 사용해서 join 한 쿼리로 조회하도록 한다.
public interface TeamRepository extends JpaRepository<Team, Long> {
@Query("select t from Team t join fetch t.students")
List<Team> findAllJoinFetch();
} @Test
void 패치_조인_모두_조회() {
// When
List<Team> teams = teamRepository.findAllJoinFetch();
log.info(teams.toString());
List<Student> students = teams.stream()
.map(Team::getStudents)
.flatMap(Collection::stream)
.collect(Collectors.toList());
// Then
assertThat(students).containsAll(학생들);
log.info(students.toString());
}Hibernate:
select
team0_.id as id1_1_0_,
students1_.id as id1_0_1_,
team0_.name as name2_1_0_,
students1_.name as name2_0_1_,
students1_.team_id as team_id3_0_1_,
students1_.team_id as team_id3_0_0__,
students1_.id as id1_0_0__
from
team team0_
inner join
student students1_
on team0_.id=students1_.team_id
2022-08-06 17:29:17.463 INFO 25737 --- [ main] com.example.demojpatest.NPlusOneTest : [Team{id=1, name='축구팀', students.size=2}, Team{id=1, name='축구팀', students.size=2}, Team{id=4, name='농구팀', students.size=2}, Team{id=4, name='농구팀', students.size=2}]
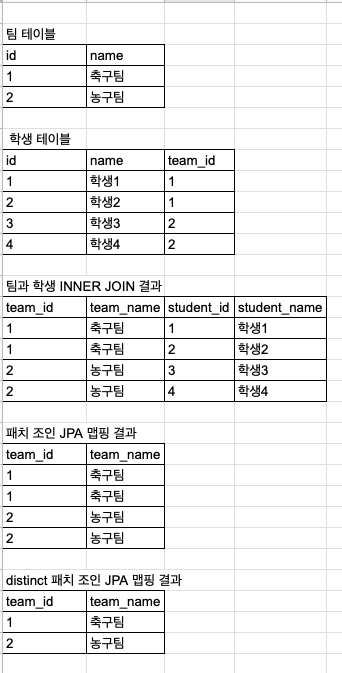
2022-08-06 17:29:17.486 INFO 25737 --- [ main] com.example.demojpatest.NPlusOneTest : [Student{id=2, name='학생1', team=Team{id=1, name='축구팀', students.size=2}}, Student{id=3, name='학생2', team=Team{id=1, name='축구팀', students.size=2}}, Student{id=2, name='학생1', team=Team{id=1, name='축구팀', students.size=2}}, Student{id=3, name='학생2', team=Team{id=1, name='축구팀', students.size=2}}, Student{id=5, name='학생3', team=Team{id=4, name='농구팀', students.size=2}}, Student{id=6, name='학생4', team=Team{id=4, name='농구팀', students.size=2}}, Student{id=5, name='학생3', team=Team{id=4, name='농구팀', students.size=2}}, Student{id=6, name='학생4', team=Team{id=4, name='농구팀', students.size=2}}]Join 쿼리로 쿼리 한 번으로 연관 엔터티까지 다 조회함으로써 N+1 문제를 해결했다. 하지만 로그를 보면 축구팀, 축구팀, 농구팀 이렇게 중복으로 Team이 조회되었다. 이 문제는 패치 조인 사용 시 발생한다. 패치 조인 join fetch 사용할 때 조심할 점은 1:N 관계에서 조회할 때 중복 데이터가 발생할 수 있기 때문에 중복제거인 distinct를 꼭 넣어주자.
public interface TeamRepository extends JpaRepository<Team, Long> {
@Query("select distinct t from Team t join fetch t.students")
List<Team> findAllJoinFetch();
}Hibernate:
select
distinct team0_.id as id1_1_0_,
students1_.id as id1_0_1_,
team0_.name as name2_1_0_,
students1_.name as name2_0_1_,
students1_.team_id as team_id3_0_1_,
students1_.team_id as team_id3_0_0__,
students1_.id as id1_0_0__
from
team team0_
inner join
student students1_
on team0_.id=students1_.team_id
2022-08-06 17:33:14.513 INFO 25951 --- [ main] com.example.demojpatest.NPlusOneTest : [Team{id=1, name='축구팀', students.size=2}, Team{id=4, name='농구팀', students.size=2}]
2022-08-06 17:33:14.535 INFO 25951 --- [ main] com.example.demojpatest.NPlusOneTest : [Student{id=2, name='학생1', team=Team{id=1, name='축구팀', students.size=2}}, Student{id=3, name='학생2', team=Team{id=1, name='축구팀', students.size=2}}, Student{id=5, name='학생3', team=Team{id=4, name='농구팀', students.size=2}}, Student{id=6, name='학생4', team=Team{id=4, name='농구팀', students.size=2}}]자세하게 설명하면, Inner Join 해서 결과를 보면 팀 개수만큼 아니라 학생수만큼 ROW 결과가 나온다. JPA에서는 Row 그대로 List <Team>로 맵핑하다 보니 같은 Team이 여러 개가 될 수 있다.
JPQL에 distinct 키워드를 넣어주면 JPA 맵핑 시, 중복을 자동으로 제거한다. (예시: "select distinct t from Team t join fetch t.students")
해결책2: 하이버네이트 @BatchSize 사용
@BatchSize를 설정하면, 사이즈만큼 쿼리를 한다. 지연 로딩 Lazy+@BatchSize를 사용하면 처음 size만큼 쿼리를 하고, size를 넘어서 접근하면 그때 쿼리를 추가로 한다. 즉시 로딩 Eager+@BatchSize를 하면, size 만큼 나눠서 여러 번 쿼리를 한 번에 호출한다.
쿼리문은 join이 아닌 in 절이다.
@BatchSize(size = 5)
@OneToMany(mappedBy = "team", fetch = FetchType.LAZY)
private List<Student> students = new ArrayList<>(); @Test
void 모든_팀을_조회() {
// When
List<Team> teams = teamRepository.findAll();
log.info(teams.toString());
List<Student> students = teams.stream()
.map(Team::getStudents)
.flatMap(Collection::stream)
.collect(Collectors.toList());
// Then
assertThat(students).containsAll(학생들);
log.info(students.toString());
}Hibernate:
select
team0_.id as id1_1_,
team0_.name as name2_1_
from
team team0_
Hibernate:
select
students0_.team_id as team_id3_0_1_,
students0_.id as id1_0_1_,
students0_.id as id1_0_0_,
students0_.name as name2_0_0_,
students0_.team_id as team_id3_0_0_
from
student students0_
where
students0_.team_id in (
?, ?, ?
)
2022-08-06 18:15:21.464 TRACE 28265 --- [ main] o.h.type.descriptor.sql.BasicBinder : binding parameter [1] as [BIGINT] - [1]
2022-08-06 18:15:21.464 TRACE 28265 --- [ main] o.h.type.descriptor.sql.BasicBinder : binding parameter [2] as [BIGINT] - [4]
2022-08-06 18:15:21.465 TRACE 28265 --- [ main] o.h.type.descriptor.sql.BasicBinder : binding parameter [3] as [BIGINT] - [7]해결책3: 하이버네이트 @Fetch(FetchMode.SUBSELECT) 사용
이 방식은 대상 엔터티 조회하는 쿼리와 연관관계를 조회하는 쿼리 2개의 쿼리가 발생한다. 연관관계 쿼리에서는 서브 쿼리 + in 절을 사용한다.
@Fetch(FetchMode.SUBSELECT)
@OneToMany(mappedBy = "team", fetch = FetchType.LAZY)
private List<Student> students = new ArrayList<>();Hibernate:
select
team0_.id as id1_1_,
team0_.name as name2_1_
from
team team0_
Hibernate:
select
students0_.team_id as team_id3_0_1_,
students0_.id as id1_0_1_,
students0_.id as id1_0_0_,
students0_.name as name2_0_0_,
students0_.team_id as team_id3_0_0_
from
student students0_
where
students0_.team_id in (
select
team0_.id
from
team team0_
)
2022-08-06 18:20:20.327 INFO 28532 --- [ main] com.example.demojpatest.NPlusOneTest : [Team{id=1, name='축구팀', students.size=2}, Team{id=4, name='농구팀', students.size=2}]
2022-08-06 18:20:20.349 INFO 28532 --- [ main] com.example.demojpatest.NPlusOneTest : [Student{id=2, name='학생1', team=Team{id=1, name='축구팀', students.size=2}}, Student{id=3, name='학생2', team=Team{id=1, name='축구팀', students.size=2}}, Student{id=5, name='학생3', team=Team{id=4, name='농구팀', students.size=2}}, Student{id=6, name='학생4', team=Team{id=4, name='농구팀', students.size=2}}]정리
- 추천하는 방법으로는 모두 기본으로
Lazy지연 로딩을 설정해두고 사용하는 것이다. - 연관 엔터티 말고 대상 엔터티만 사용하는 경우가 많기 때문이다. 연관 엔터티 모두를 조회하는 경우는 많이 없다.
- 즉시 로딩을 사용하다보면, 성능 최적화가 어렵다. 왜냐하면, 즉시 로딩이 연속으로 발생해서 예상치 못한 SQL이 실행될 수 있기 때문이다.
- 최적화가 필요한 곳만
패치 조인을 사용하는 걸 권장한다.
JPA의 페치 전략 기본값
- @OneToOne, @ManyToOne: 즉시로딩
- @OneToMany, @ManyToMany: 지연 로딩